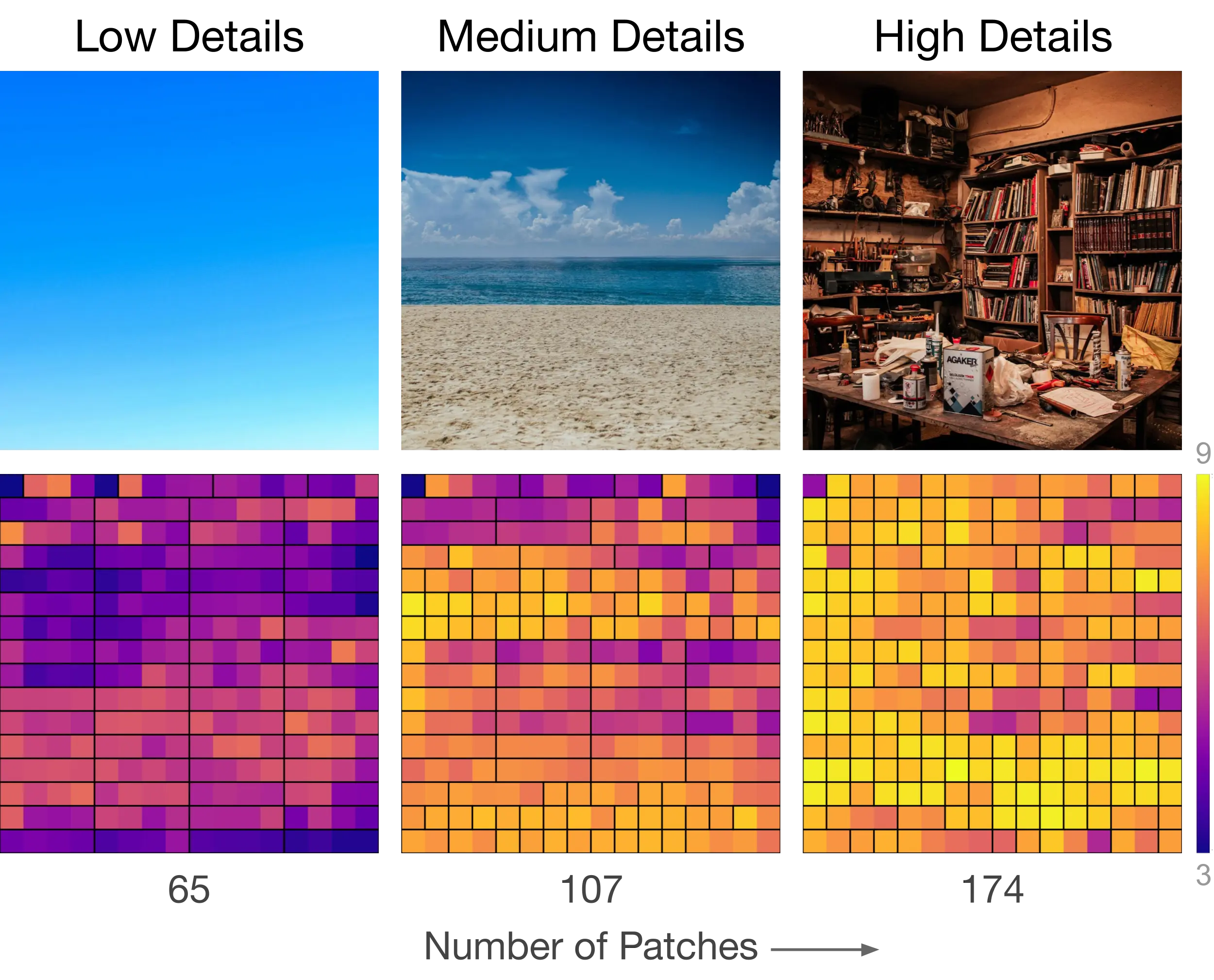
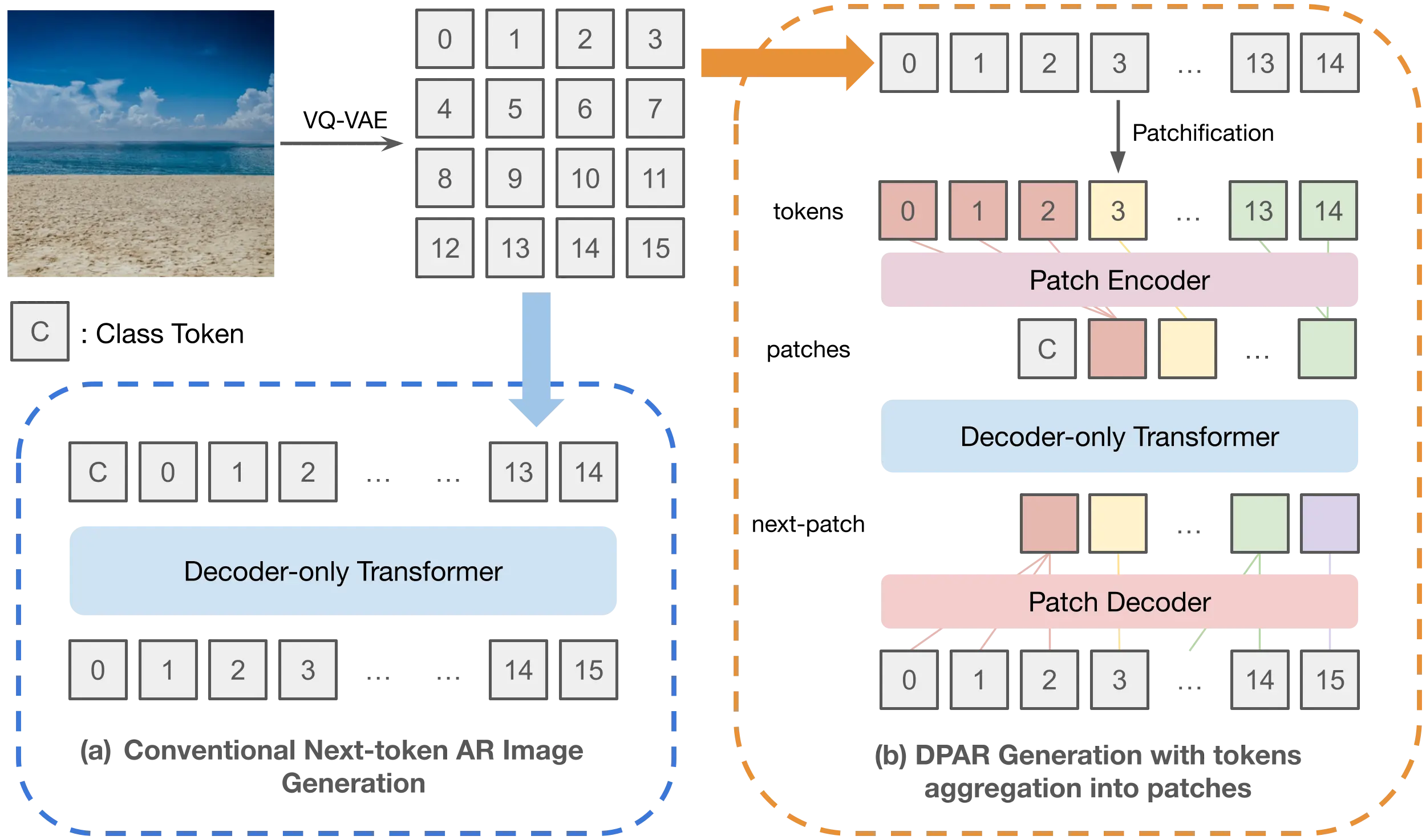
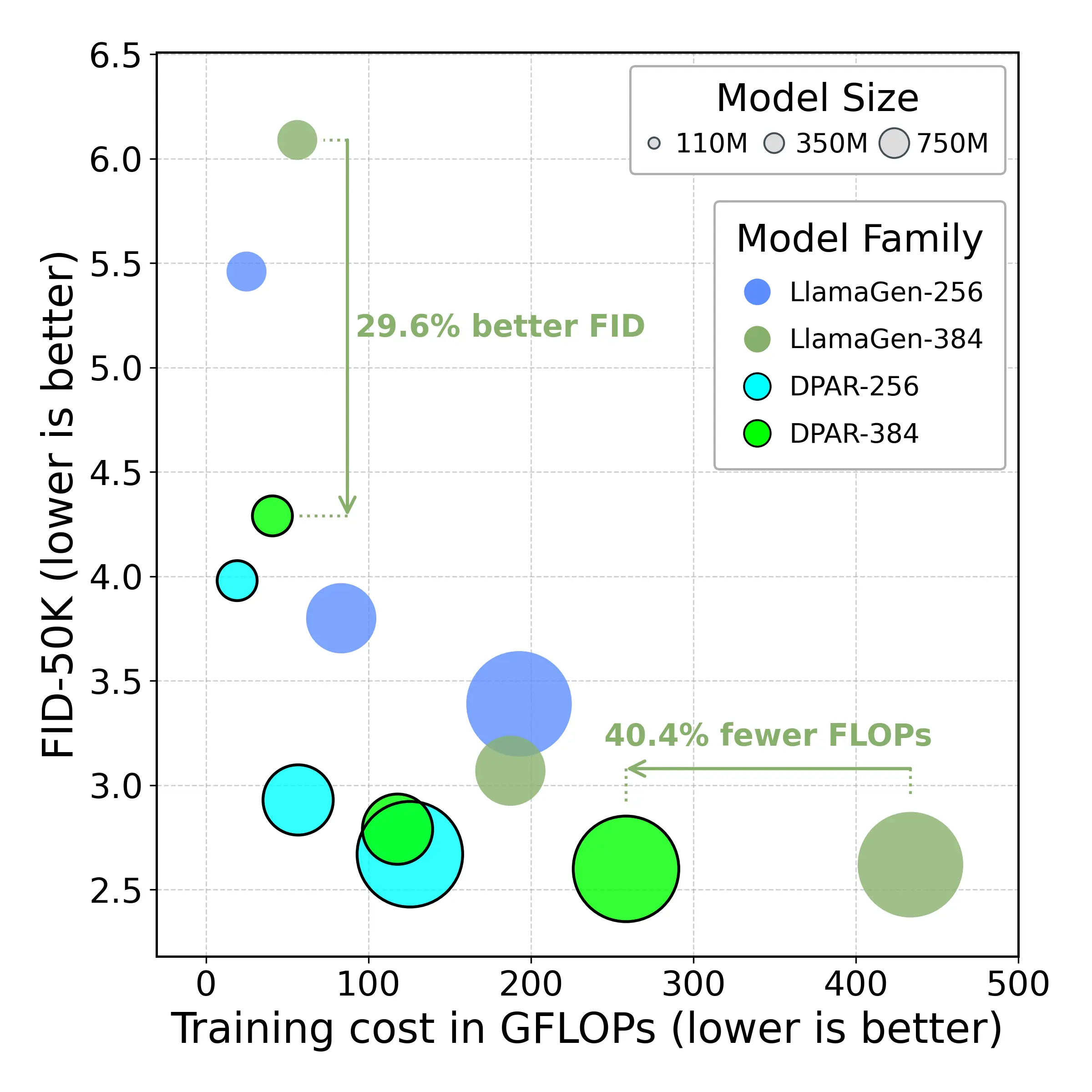
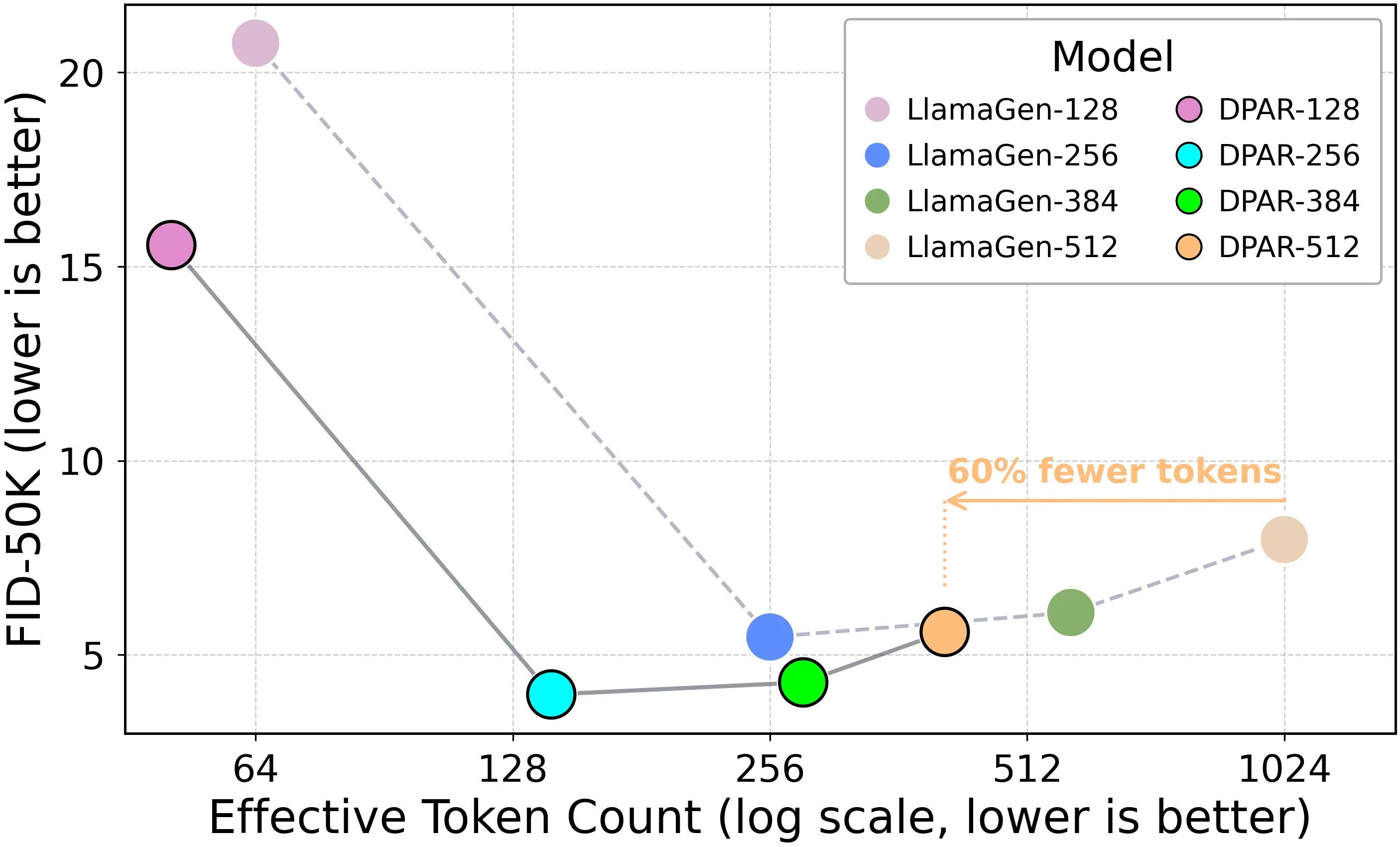
- Havtorn, Jakob Drachmann, et al. "Msvit: Dynamic mixed-scale tokenization for vision transformers." ICCV 2023.
- Shen, Junhong, et al. "Cat: Content-adaptive image tokenization." arXiv:2501.03120 (2025).
- Ma, Xu, et al. "Token-shuffle: Towards high-resolution image generation with autoregressive models." arXiv:2504.17789 (2025).
- Pagnoni, Artidoro, et al. "Byte latent transformer: Patches scale better than tokens." arXiv:2412.09871 (2024).
- Pang, Ziqi, et al. "Randar: Decoder-only autoregressive visual generation in random orders." CVPR 2025.

Fig. 1: Selected samples from our class-conditional DPAR-384-XL model trained on ImageNet.